Big Data & Hadoop

Feb 12, 2019 • 5 views
Hadoop is AN ASCII text file software package framework for storing information and running applications on clusters of goods hardware.
It provides large storage for any quite information, monumental process power and therefore the ability to handle nearly limitless simultaneous tasks or jobs.

History of Hadoop
As the World Wide internet grew within the late decade and early 2000s, search engines, and indexes were created to help locate relevant information amid the text-based content.
In the early years, search results came back by humans.
But because the internet grew from dozens to uncountable pages, automation was required.
Web crawlers were created, many as university-led research projects and search engine start-ups took off (Google, Yahoo, Bing etc.).

Why is Hadoop important?
Ability to store and method Brobdingnagian amounts of any quite information, quickly-With information volumes and varieties perpetually increasing, especially from social media and the Internet of Things (IoT), that's a key consideration.
Computing power- Hadoop's distributed computing model processes massive information quick.
The additional computing nodes you utilize, the additional process power you have got.
Fault tolerance- info and application method unit protected against hardware failure.
If a node goes down, jobs square measure mechanically redirected to different nodes to form positive the distributed computing doesn't fail.
Multiple copies of all data are stored automatically.
Flexibility- in contrast to ancient relative databases, you don’t have to preprocess data before storing it.
You can store the maximum amount of information as you would like and choose a way to use it later.
That includes unstructured information like text, images, and videos.
Low cost- The ASCII text file framework is free and uses goods hardware to store massive quantities of information.
Scalability- you'll simply grow your system to handle additional information just by adding nodes.
Little administration is required.

Some of the exciting facts concerning massive information square measure :
As per Forbes by the year 2020, approximately 1.7 megabytes of information will be generated each second.
The Hadoop market is anticipated to cross $ one billion by 2020 with a compound rate of fifty-eight.
However, lesser than 0.5% of the data is analyzed at the moment.

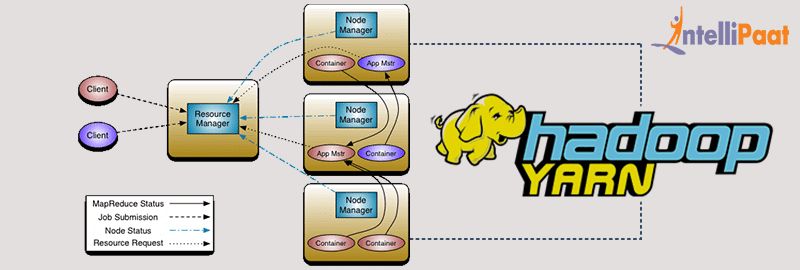
Hadoop Components and Daemons

There are 2 layers in Hadoop –HDFS layer and Map reduce layer and 5 daemons which run on Hadoop in these 2 layers.
Daemons square measure the processes that run within the background.
Recommended

The Advent Of Information And Technology In The 21st Century"